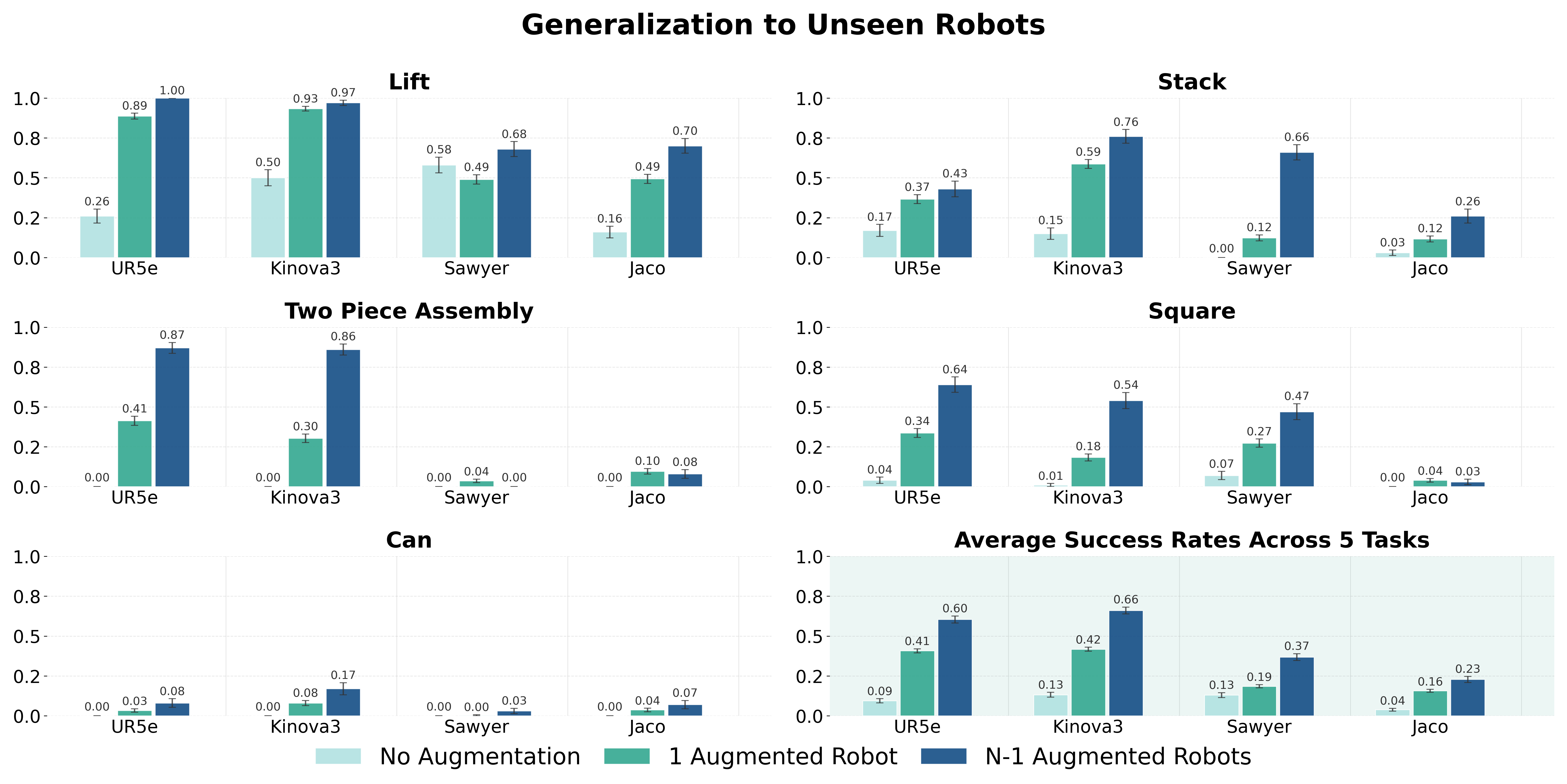
TODO: Add more videos
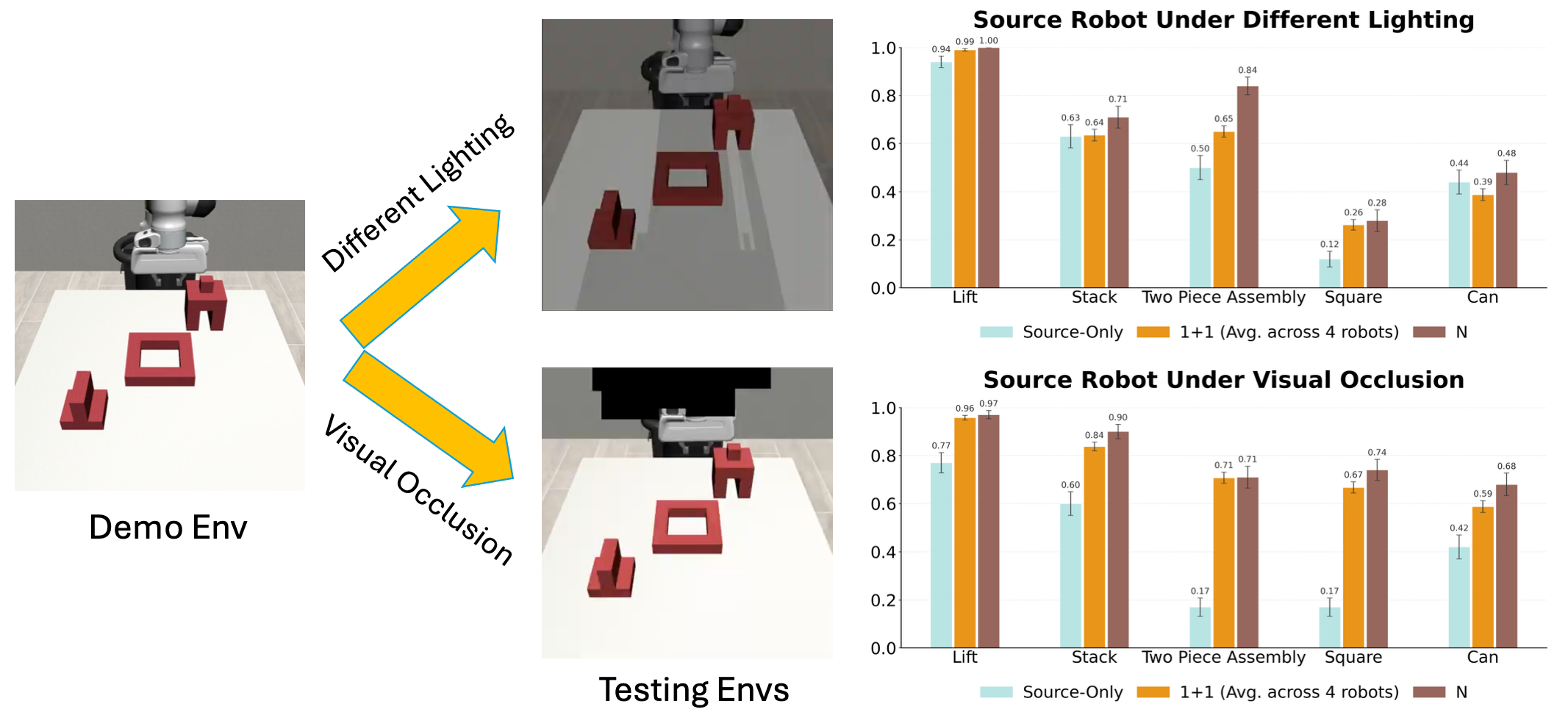
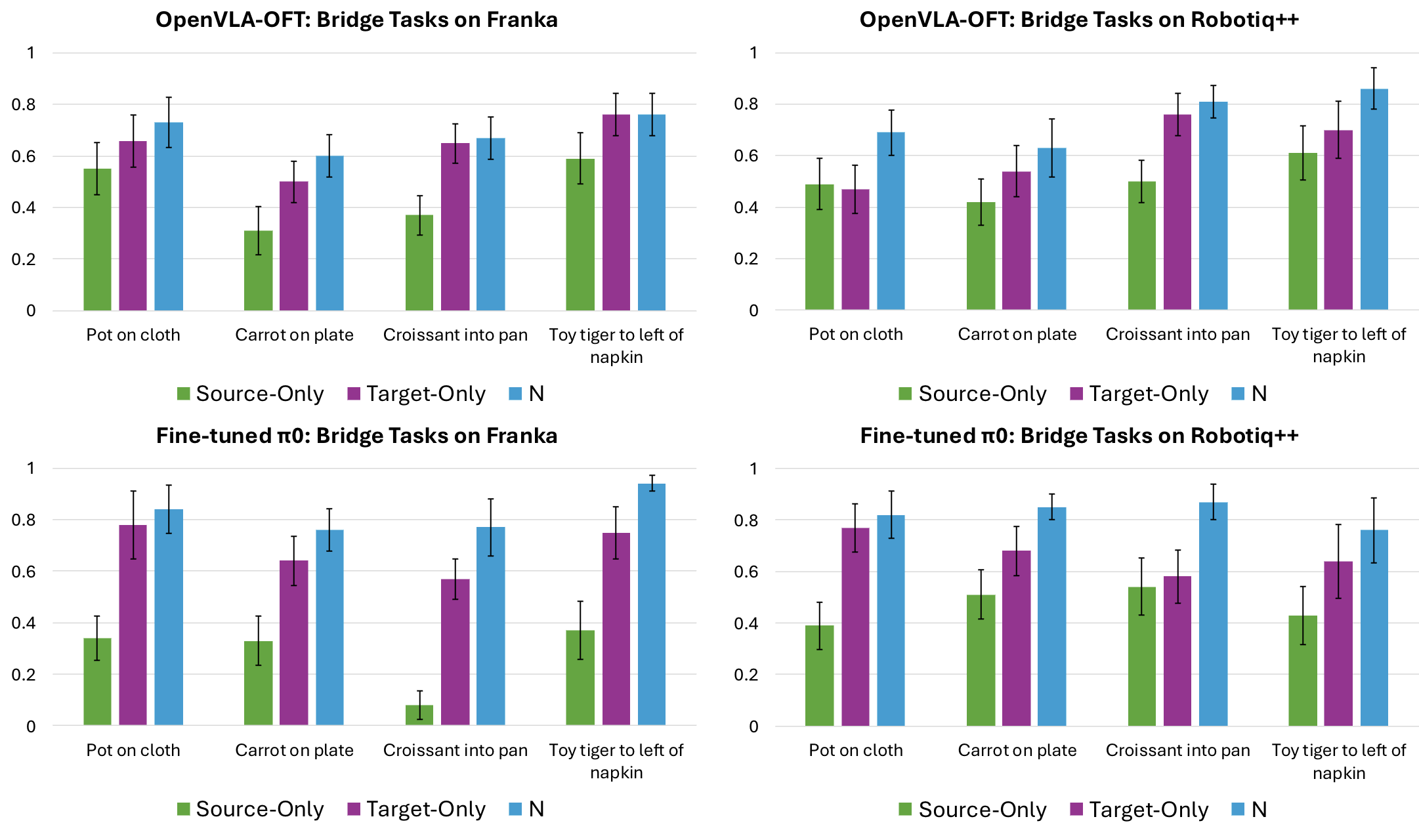
TODO: Add text here.
Datasets: CC BY 4.0 (attribution required; state your modifications in derivatives).
Code: Apache-2.0 / MIT (match your repo choice).
Responsible Use: No personal data; research/robotics use; do not deploy in unlawful or harmful contexts.


